代码
from pandas import DataFrame
import numpy as np
import pandas as pd
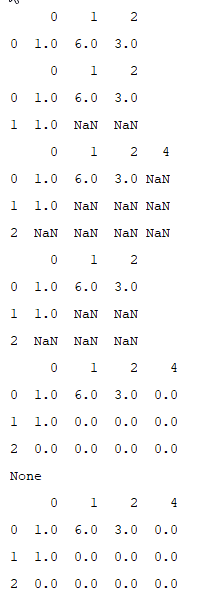
data = { 'city': ['shanghai', 'shanghai', 'shanghai', 'beijing', 'beijing'],
'year': [2016, 2017, 2018, 2017, 2018],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data)
frame2 = DataFrame(data, columns=['year', 'city', 'pop'])
print(frame)
print(frame2)运行
代码
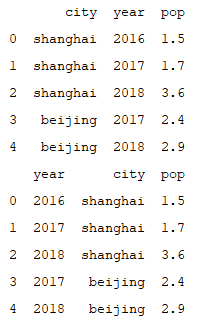
print(frame['city'])
print('--------------------------')
print(frame.city)运行

print(frame2)
#增加新的一列
frame2 ['new'] = 100
print(frame2)运行
代码
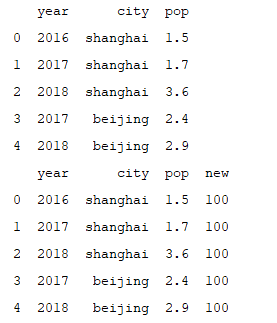
#增加新的一列
frame2 ['new'] = 100
print(frame2)
#根据值增加一列
frame2['cap'] = frame2.city == 'beijing'
print(frame2)运行
代码
pop = { 'beijing': {2018:1.5, 2019:2.0},
'shanghai': {2018:2.2, 2019:3.3}
}
frame3 = DataFrame(pop)
print(frame3)
print(frame3.T) #行列式的转置运行
代码
obj4 = Series( [4.5, 7.2, 5.3, 3.6], index= ['b', 'd', 'c', 'a'])
print(obj4)
obj5 = obj4.reindex(['a', 'b', 'c', 'd', 'e'])
print(obj5)
obj5 = obj4.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0)
print(obj5)运行

代码
obj6 = Series(['blue', 'purple', 'yellow'], index= [0, 2, 4])
print( obj6.reindex(range(6)))
print( obj6.reindex(range(6), method='ffill')) #bfill运行

代码
from numpy import nan as NA
data = Series( [1, NA, 2] )
print(data)
print(data.dropna())运行

代码
data2 = DataFrame(
[
[1, 6, 3], [1, NA, NA], [NA, NA, NA]
]
)
print(data2.dropna())
print(data2.dropna(how='all')) #删除全部为NA的行
data2 [4] = NA
print(data2)
print(data2.dropna(axis=1,how='all')) #删除全部为NA的列
#将NA全部赋值
print(data2.fillna(0)) #不对数据做出改变
print(data2.fillna(0, inplace = True)) #改变数据
print(data2)运行