代码
#!/usr/bin/env python
# coding: utf-8
# In[1]:
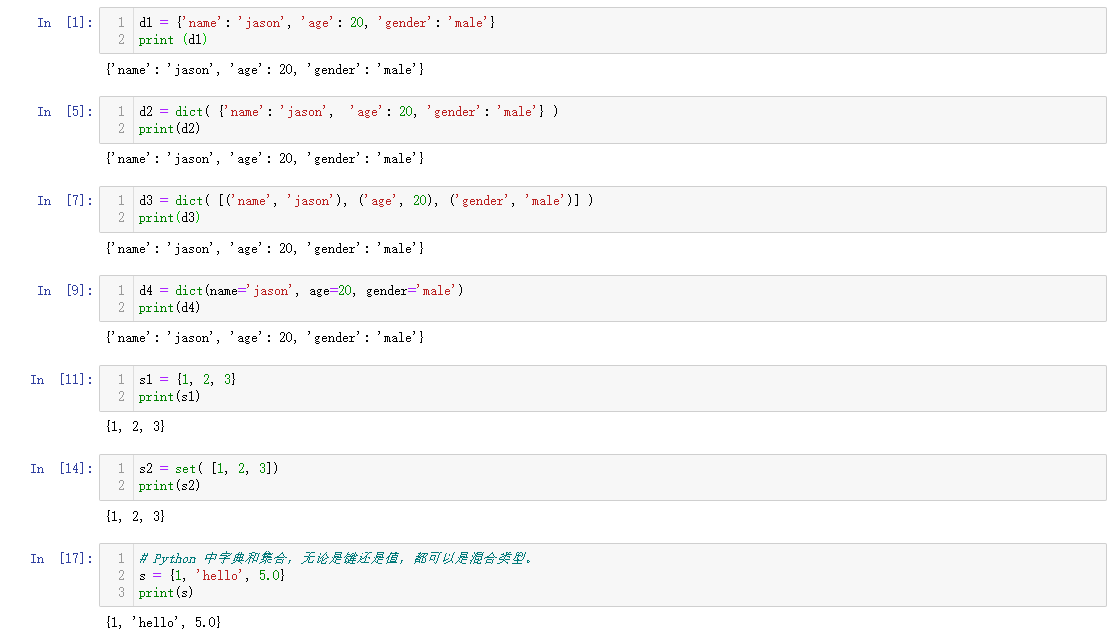
d1 = {'name': 'jason', 'age': 20, 'gender': 'male'}
print (d1)
# In[5]:
d2 = dict( {'name': 'jason', 'age': 20, 'gender': 'male'} )
print(d2)
# In[7]:
d3 = dict( [('name', 'jason'), ('age', 20), ('gender', 'male')] )
print(d3)
# In[9]:
d4 = dict(name='jason', age=20, gender='male')
print(d4)
# In[11]:
s1 = {1, 2, 3}
print(s1)
# In[14]:
s2 = set( [1, 2, 3])
print(s2)
# In[17]:
# Python 中字典和集合,无论是键还是值,都可以是混合类型。
s = {1, 'hello', 5.0}
print(s)
# In[4]:
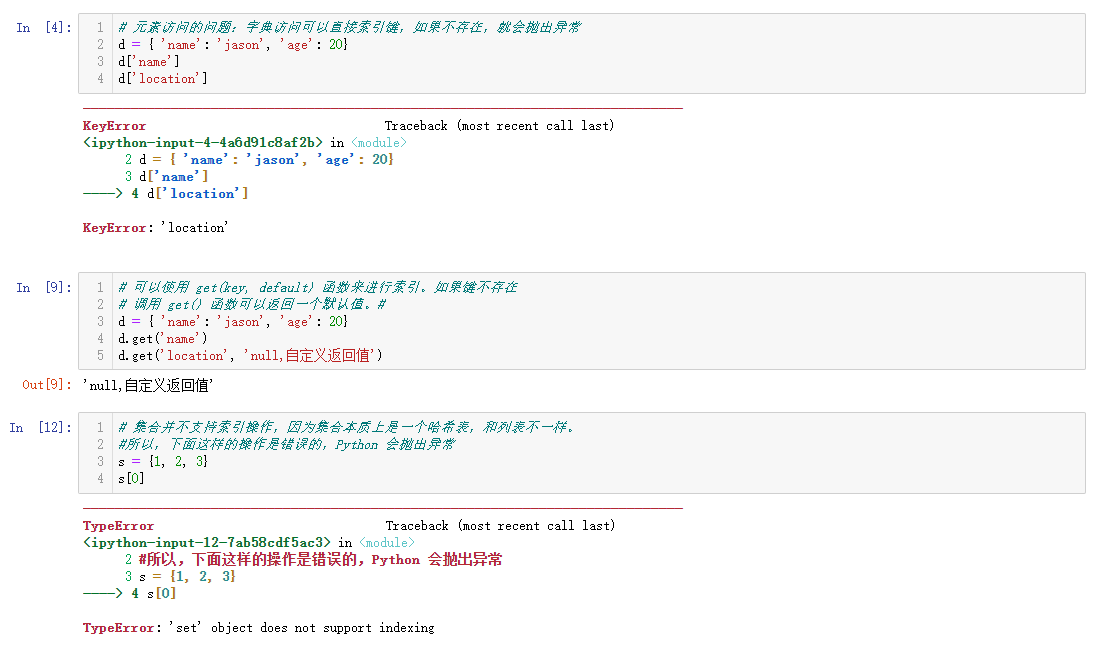
# 元素访问的问题:字典访问可以直接索引键,如果不存在,就会抛出异常
d = { 'name': 'jason', 'age': 20}
d['name']
d['location']
# In[9]:
# 可以使用 get(key, default) 函数来进行索引。如果键不存在
# 调用 get() 函数可以返回一个默认值。#
d = { 'name': 'jason', 'age': 20}
d.get('name')
d.get('location', 'null,自定义返回值')
# In[12]:
# 集合并不支持索引操作,因为集合本质上是一个哈希表,和列表不一样。
#所以,下面这样的操作是错误的,Python 会抛出异常
s = {1, 2, 3}
s[0]
# In[18]:
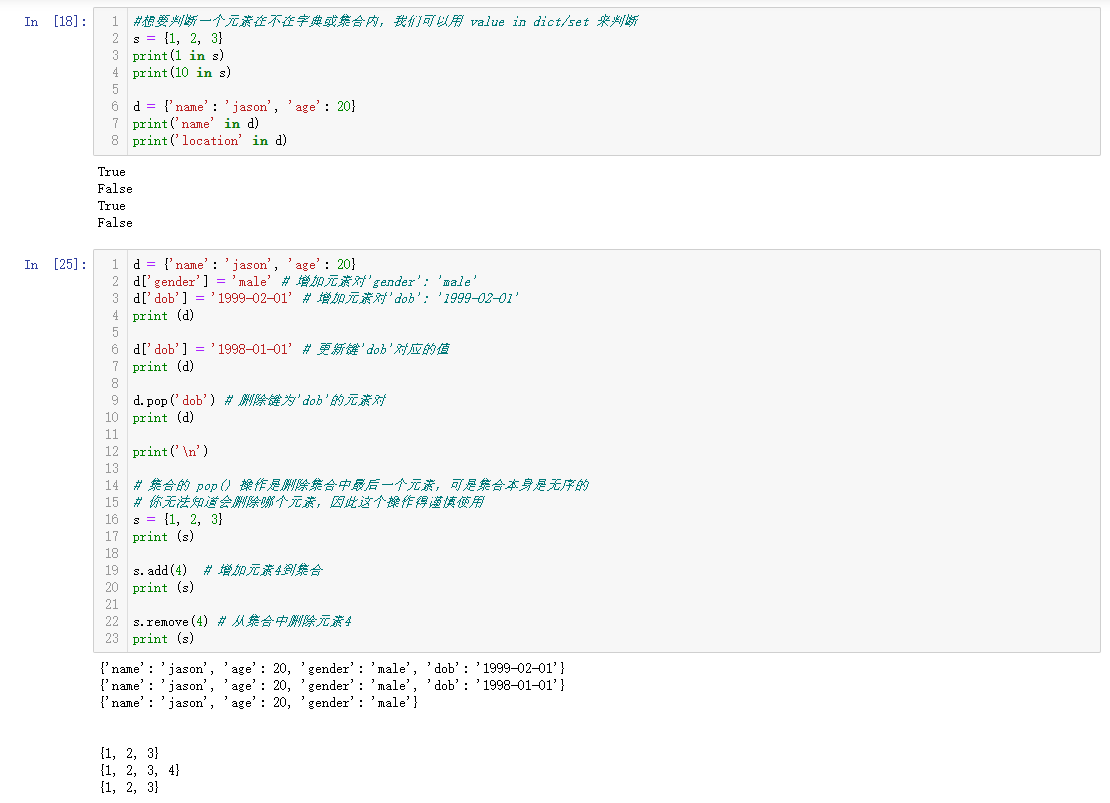
#想要判断一个元素在不在字典或集合内,我们可以用 value in dict/set 来判断
s = {1, 2, 3}
print(1 in s)
print(10 in s)
d = {'name': 'jason', 'age': 20}
print('name' in d)
print('location' in d)
# In[25]:
d = {'name': 'jason', 'age': 20}
d['gender'] = 'male' # 增加元素对'gender': 'male'
d['dob'] = '1999-02-01' # 增加元素对'dob': '1999-02-01'
print (d)
d['dob'] = '1998-01-01' # 更新键'dob'对应的值
print (d)
d.pop('dob') # 删除键为'dob'的元素对
print (d)
print('\n')
# 集合的 pop() 操作是删除集合中最后一个元素,可是集合本身是无序的
# 你无法知道会删除哪个元素,因此这个操作得谨慎使用
s = {1, 2, 3}
print (s)
s.add(4) # 增加元素4到集合
print (s)
s.remove(4) # 从集合中删除元素4
print (s)
# In[31]:
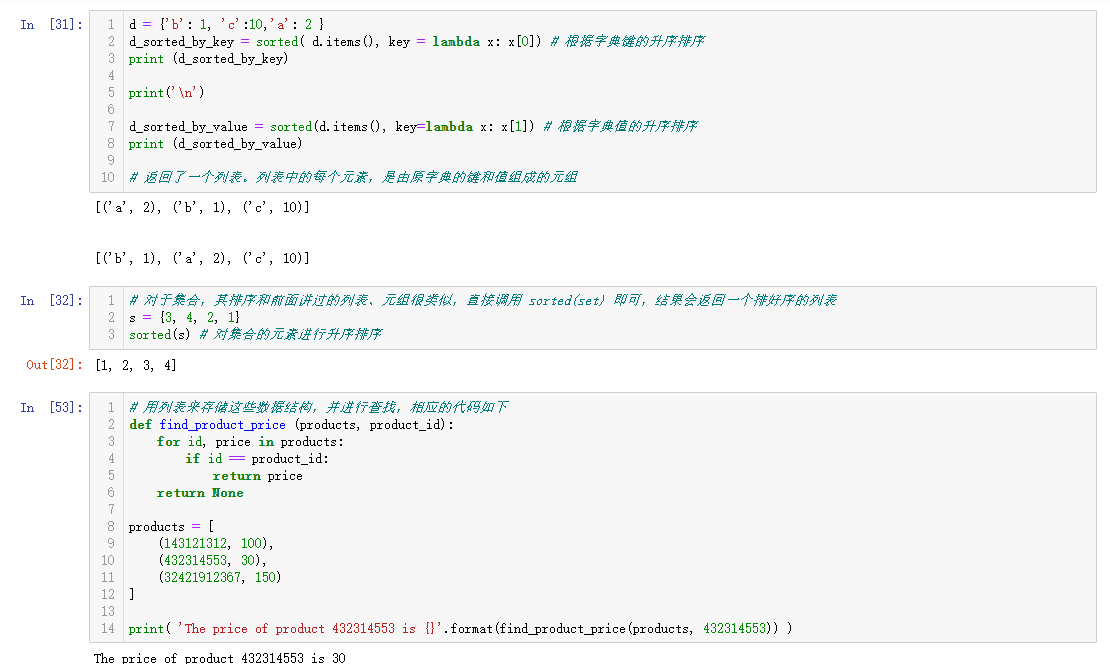
d = {'b': 1, 'c':10,'a': 2 }
d_sorted_by_key = sorted( d.items(), key = lambda x: x[0]) # 根据字典键的升序排序
print (d_sorted_by_key)
print('\n')
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1]) # 根据字典值的升序排序
print (d_sorted_by_value)
# 返回了一个列表。列表中的每个元素,是由原字典的键和值组成的元组
# In[32]:
# 对于集合,其排序和前面讲过的列表、元组很类似,直接调用 sorted(set) 即可,结果会返回一个排好序的列表
s = {3, 4, 2, 1}
sorted(s) # 对集合的元素进行升序排序
# In[53]:
# 用列表来存储这些数据结构,并进行查找,相应的代码如下
def find_product_price (products, product_id):
for id, price in products:
if id == product_id:
return price
return None
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150)
]
print( 'The price of product 432314553 is {}'.format(find_product_price(products, 432314553)) )
# In[55]:
# 字典的内部组成是一张哈希表,你可以直接通过键的哈希值,找到其对应的值
products = {
143121312: 100,
432314553: 30,
32421912367: 150
}
print('The price of product 432314553 is {}'.format(products[432314553]))
# In[57]:
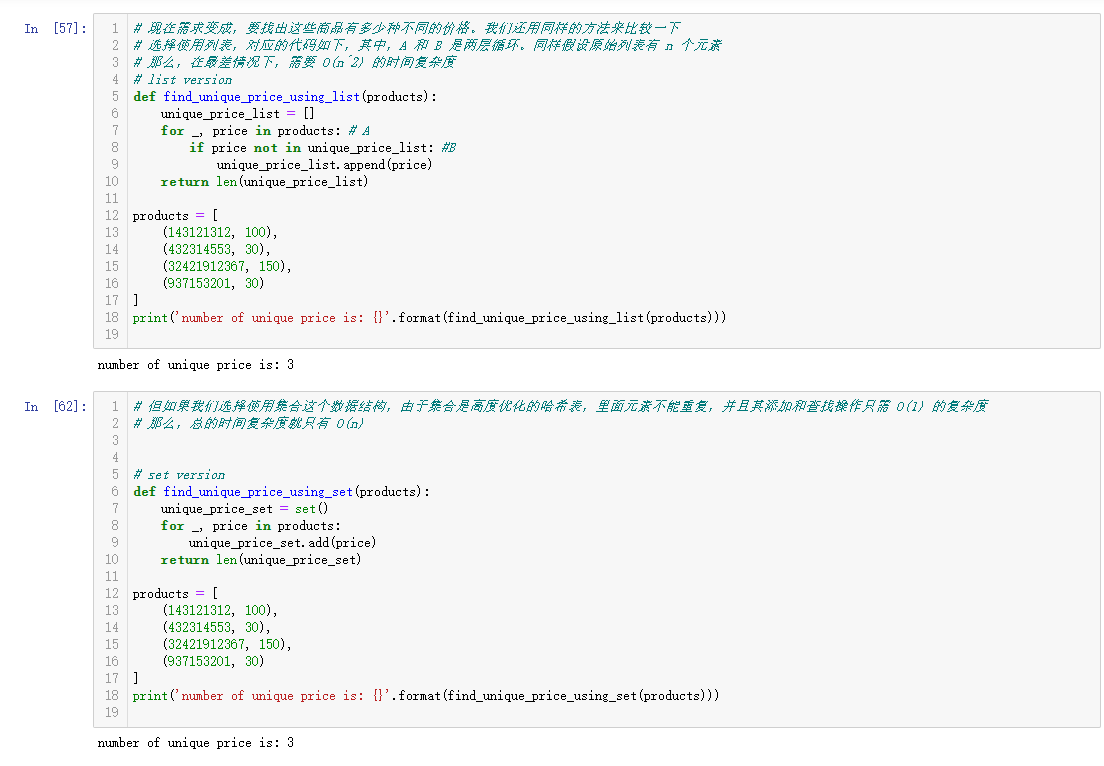
# 现在需求变成,要找出这些商品有多少种不同的价格。我们还用同样的方法来比较一下
# 选择使用列表,对应的代码如下,其中,A 和 B 是两层循环。同样假设原始列表有 n 个元素
# 那么,在最差情况下,需要 O(n^2) 的时间复杂度
# list version
def find_unique_price_using_list(products):
unique_price_list = []
for _, price in products: # A
if price not in unique_price_list: #B
unique_price_list.append(price)
return len(unique_price_list)
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_list(products)))
# In[62]:
# 但如果我们选择使用集合这个数据结构,由于集合是高度优化的哈希表,里面元素不能重复,并且其添加和查找操作只需 O(1) 的复杂度
# 那么,总的时间复杂度就只有 O(n)
# set version
def find_unique_price_using_set(products):
unique_price_set = set()
for _, price in products:
unique_price_set.add(price)
return len(unique_price_set)
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_set(products)))截图