代码
#!/usr/bin/env python
# coding: utf-8
# In[5]:
name = input('your name: ')
gender = input('your are a boy? (y/n) ')
welcome_str = 'Welcome to the matrix {prefix} {name}.'
welcome_dic = {
'prefix': 'Mr.' if gender == 'y' else 'Mrs',
'name': name
}
print('authoring...')
print(welcome_str.format(**welcome_dic))
# In[11]:
a = input()
b = input()
print('a + b ={}'.format(a + b))
print('type of a is {}, type of b is {}'.format(type(a), type(b)))
print('a + b = {}'.format(int(a) + int(b)))
# In[16]:
import json
params = {
'symbol': '123456',
'type': 'limit',
'price': 123.4,
'amount': 23
}
params_str = json.dumps(params)
print('after json serialization')
print('type of params_str = {}, params_str = {}'.format(type(params_str), params_str))
print('\n')
original_params = json.loads(params_str)
print('after json deserialization')
print('type of original_params = {}, original_params = {}'.format(type(original_params), original_params))
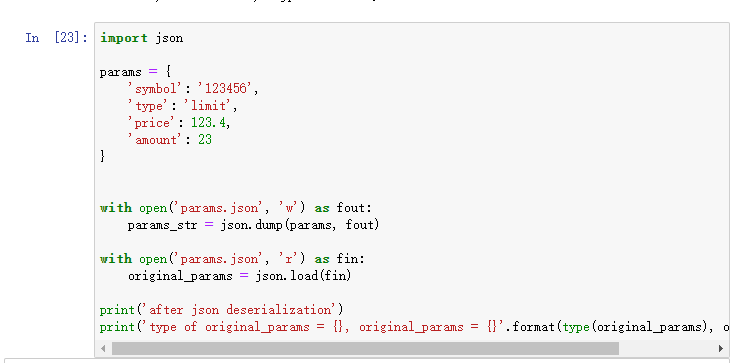
# In[23]:
import json
params = {
'symbol': '123456',
'type': 'limit',
'price': 123.4,
'amount': 23
}
with open('params.json', 'w') as fout:
params_str = json.dump(params, fout)
with open('params.json', 'r') as fin:
original_params = json.load(fin)
print('after json deserialization')
print('type of original_params = {}, original_params = {}'.format(type(original_params), original_params))
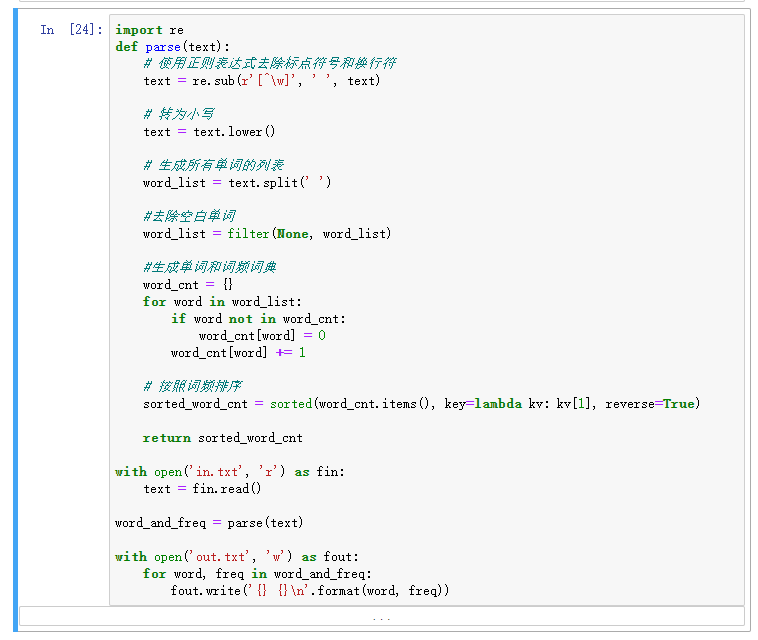
# In[24]:
import re
def parse(text):
# 使用正则表达式去除标点符号和换行符
text = re.sub(r'[^\w]', ' ', text)
# 转为小写
text = text.lower()
# 生成所有单词的列表
word_list = text.split(' ')
#去除空白单词
word_list = filter(None, word_list)
#生成单词和词频词典
word_cnt = {}
for word in word_list:
if word not in word_cnt:
word_cnt[word] = 0
word_cnt[word] += 1
# 按照词频排序
sorted_word_cnt = sorted(word_cnt.items(), key=lambda kv: kv[1], reverse=True)
return sorted_word_cnt
with open('in.txt', 'r') as fin:
text = fin.read()
word_and_freq = parse(text)
with open('out.txt', 'w') as fout:
for word, freq in word_and_freq:
fout.write('{} {}\n'.format(word, freq))截图